0x00整除 ,讲解了一些整除的基础知识,理解这些内容是我们学习接下来的内容的基础。
整除的定义:若整数 n 除以整数 d 的余数为 0,即 d 能整除 n ,则称 d 是 n 的约数,n 是 d 的倍数,记为 d ∣ n d\mid n d ∣ n
性质1.1: a ∣ b , b ∣ c ⇒ a ∣ c a\mid b,b\mid c \Rightarrow a | c a ∣ b , b ∣ c ⇒ a ∣ c
性质1.2:a ∣ b ⇒ a ∣ b c a∣b⇒a∣bc a ∣ b ⇒ a ∣ b c
性质1.3: $a ∣ b , a ∣ c ⇒ a ∣ k b ± lc $(k 与 l ll 均为任意的整数)。(都有公因子 a,正确性显然)
性质1.3推论:k 1 , k 2 互质,则 k 1 + k 2 与 k 1 × k 2 互质 k_1 , k_2互质,则 k_1+k_2与k_1×k_2互质 k 1 , k 2 互 质 , 则 k 1 + k 2 与 k 1 × k 2 互 质 k 1 + k 2 与 k 1 × k 2 k_1+k_2与k_1×k_2 k 1 + k 2 与 k 1 × k 2
性质1.4:a ∣ b , b ∣ a ⇒ a = ± b a∣b,b∣a⇒a=±b a ∣ b , b ∣ a ⇒ a = ± b
性质1.5:$a = k b ± c ⇒ a , b $ 的公因数与 b , c 的公因数完全相同
性质1.6:若 $a ∣ b c $,且 a与 c 互质,则 a ∣ b a\mid b a ∣ b
定义: 素数(又称质数)是只有 1 和它本身两个因数的数。 规定 1 既非素数也非合数。特殊的,2是唯一的偶素数。
素数定理:设 π ( x )为 1 到 x 中素数的个数。
其中:
π ( n ) = − 1 + ∑ k = 1 x ⌊ cos 2 ⌊ π ( n − 1 ) ! + 1 n ⌋ ⌋ π ( n ) =-1+\sum_{k=1}^x\lfloor \cos^2\lfloor\pi\cfrac{(n-1)!+1}{n}\rfloor \rfloor
π ( n ) = − 1 + k = 1 ∑ x ⌊ cos 2 ⌊ π n ( n − 1 ) ! + 1 ⌋ ⌋
尝试求极限发现(其中$ \ln(x)$ 表示x 的自然对数):
lim x − > ∞ π ( x ) ( x ln ( x ) ) = 1 \lim_{x->∞}\cfrac{π(x)}{(\frac{x}{\ln(x)})}=1 lim x − > ∞ ( l n ( x ) x ) π ( x ) = 1
即可得到定理:
定理2.1: 在自然数集中,小于 n 的质数约有 $\cfrac {n}{\ln(n)} $ 个。
由该定理可知,是 int 范围内的素数的个数并不会很多,其中 int 范围内的素数间距大概是 1 0 2 10^2 1 0 2
定理2.2: (伯特兰—切比雪夫定理) (伯特兰 — 切比雪夫定理) ( 伯 特 兰 — 切 比 雪 夫 定 理 ) n > 3,则至少存在一个质数 p ,符合 n < p < 2 n − 2 n < p < 2 n − 2 n < p < 2 n − 2 n < p < 2 n n < p < 2n n < p < 2 n
接下来介绍的四种算法均为单个素数 的判定方法。
1.试除法
一个数如果不是素数,则一定能被一个小于它自己的数整除。假设一个数能整除 n n n n n n ,则有 ,则有 , 则 有 ,即 ,即 , 即
时间复杂度:O ( n ) O(\sqrt{n}) O ( n )
1 2 3 4 5 6 7 8 inline bool is_prime (int x) { if (x < 2 ) return false ; for (register int i = 2 ; i * i <= x; ++ i) if (x % i == 0 ) return false ; return true ; }
2.kn+i 法k = 6 k=6 k = 6 6 n + 3 , 6 n + 4 , 6 n + 6 6n+3,6n+4,6n+6 6 n + 3 , 6 n + 4 , 6 n + 6 2 , 3 , 2 , 6 2 , 3 , 2 , 6 2 , 3 , 2 , 6 O ( n 1 3 ) O(n^\frac{1}{3}) O ( n 3 1 )
下面是$kn+i $法 k = 30 k = 30 k = 3 0
1 2 3 4 5 6 7 bool isPrime (ll n) if (n == 2 || n == 3 || n == 5 )return 1 ; if (n % 2 == 0 || n % 3 == 0 || n % 5 == 0 || n == 1 ) return 0 ; ll c = 7 , a[8 ] = {4 ,2 ,4 ,2 ,4 ,6 ,2 ,6 }; while (c * c <= n) for (auto i : a){if (n % c == 0 )return 0 ; c += i;} return 1 ; }
3.预处理法n \sqrt
n n n \sqrt n
n n \sqrt n n s = n ln n s=\dfrac{n}{\ln n} s = ln n n O ( n ln n ) O(\dfrac{n}{\ln n}) O ( ln n n )
4.Miller−Rabin 判定法M i l l e r − R a b i n M i l l e r − R a b i n \tt Miller-RabinMiller−Rabin M i l l e r − R a b i n M i l l e r − R a b i n
M i l l e r − R a b i n M i l l e r − R a b i n \tt Miller-RabinMiller−Rabin M i l l e r − R a b i n M i l l e r − R a b i n a p − 1 ≡ 1 ( m o d p ) a^{p-1}\equiv 1\ (\mod p) a p − 1 ≡ 1 ( m o d p )
然而我们不可能试遍所有和 p 互素的正整数,这样的话复杂度反而更高,事实上我们只需要取比 p 小的几个素数进行测试就行了。
具体判断 n 是否为素数的算法如下:
如果 n==2 ,返回 true;如果 n<2 || !(n & 1), 返回 false;否则跳到 (2) 。
令 n = m ∗ ( 2 k ) + 1 n = m *(2 ^ k) + 1 n = m ∗ ( 2 k ) + 1 n − 1 = m × ( 2 k ) n - 1 = m \times (2 ^ k) n − 1 = m × ( 2 k )
枚举小于 n的素数 p(至多枚举 10个),对每个素数执行费马测试,费马测试如下:计算 p r e = p m pre = p ^ m % n p r e = p m pre 等于1,则该测试失效,继续回到 3) 测试下一个素数;否则进行 k次计算$ next = pre ^ 2 \mod n$,如果 next == 1 && pre != 1 && pre != n-1 则n必定是合数,直接返回;k次计算结束判断 pre 的值,如果不等于 1,必定是合数。
10次判定完毕,如果 n都没有检测出是合数,那么 n为素数。
时间复杂度为O ( k log n ) O(k\log n) O ( k log n )
以下为该方法的证明:
\begin{align}
x^{k\times2^e}-1&=(x^{k\times 2^{e-1}})^2-1\\
&=(x^{k\times 2^{e-1}}+1)\times(x^{k\times 2^{e-1}}-1)\\
&=(x^{k\times 2^{e-1}}+1)(x^{k\times 2^{e-2}}+1)(x^{k\times 2^{e-2}}-1)\\
&=·······\\
&=(x^{k\times 2^{e-1}}+1)······(x^{2k}+1)(x^{k}+1)(x^{k}-1)
\end{align}
如果p是素数,1 < = a < = p 1<=a<=p 1 < = a < = p a p − 1 ≡ 1 ( m o d p ) a^{p-1}\equiv1(\mod p) a p − 1 ≡ 1 ( m o d p )
设p − 1 = k × 2 e p-1= k\times2^e p − 1 = k × 2 e
( a k − 1 ) ( a k + 1 ) ( a 2 k + 1 ) ( a 4 k + 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ( a k × 2 e − 1 ) ≡ 0 ( m o d n ) (a^k-1)(a^k+1)(a^{2k}+1)(a^{4k}+1)······(a^{k\times2^{e-1}})\equiv0(\mod n) ( a k − 1 ) ( a k + 1 ) ( a 2 k + 1 ) ( a 4 k + 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ( a k × 2 e − 1 ) ≡ 0 ( m o d n )
也就是:
a k ≡ 1 m o d n a^k\equiv1\mod n a k ≡ 1 m o d n a k × 2 i ≡ − 1 m o d n ( i ∈ 0 , . . . , e − 1 ) a^{k\times2^i}\equiv-1\mod n(i\in{0,...,e-1}) a k × 2 i ≡ − 1 m o d n ( i ∈ 0 , . . . , e − 1 )
如果要检验n n n n − 1 = k × 2 e n-1=k\times2^e n − 1 = k × 2 e e e e k k k a a a n n n a a a
要判断n是否为素数,对于一定范围内的n,只要以一定范围内a为底就可以保证这是一个确定性算法了。下面详细说明:
if n < 1 373 653 a = 2 and 3.
if n < 9 080 191 a = 31 and 73.
if n < 4 759 123 141 a = 2, 7, and 61.
if n < 2 152 302 898 747 a = 2, 3, 5, 7, and 11.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 int qmul (int a,int b ,int mod) { a%=mod; b%=mod; int c=(long double )a*b/mod; int ans=a*b-c*mod; return (ans%mod+mod)%mod; } int qpow (int flor,int m,int n) { int ret=1 ; while (m) { if (m%2 ==1 )ret=qmul(ret,flor,n); flor=qmul(flor,flor,n); m/=2 ; } return (ret+n)%n; } bool miller_rabbin_one (int n) { if (n==2 )return true ; if (n<2 || n%2 ==0 )return false ; int m=n-1 ; int k=0 ; while (m%2 ==0 ) { m/=2 ;k++;} int recordk=k; vector <int > primes = {2 , 3 , 5 , 7 , 11 , 13 , 17 , 19 , 23 ,29 ,31 ,37 }; for (int inode : primes) { if (n==inode)return true ; int pre=qpow(inode,m,n),next=pre; if (pre==1 ) continue ; k=recordk; while (k--) { next=qmul(pre,pre,n); if (next==1 && pre!=1 && pre!=n-1 )return false ; pre=next; } if (pre!=1 )return false ; } return true ; }
通过上文的学习,我们了解了判断单个数是否为素数的四种常用方法,那么对于一个很大范围内的所有数的素数判定,若我们直接对于每一个数都使用一次素数判定法,如此庞大的时间复杂度我们是无法承担的,因此引入了对于大规模数的素数判定方法:质数筛法。
质数筛法一般分为埃氏筛和线性筛。
埃氏筛没有线性筛时间复杂度好,不常用,但是他的时间复杂度分析方法却比较常用。
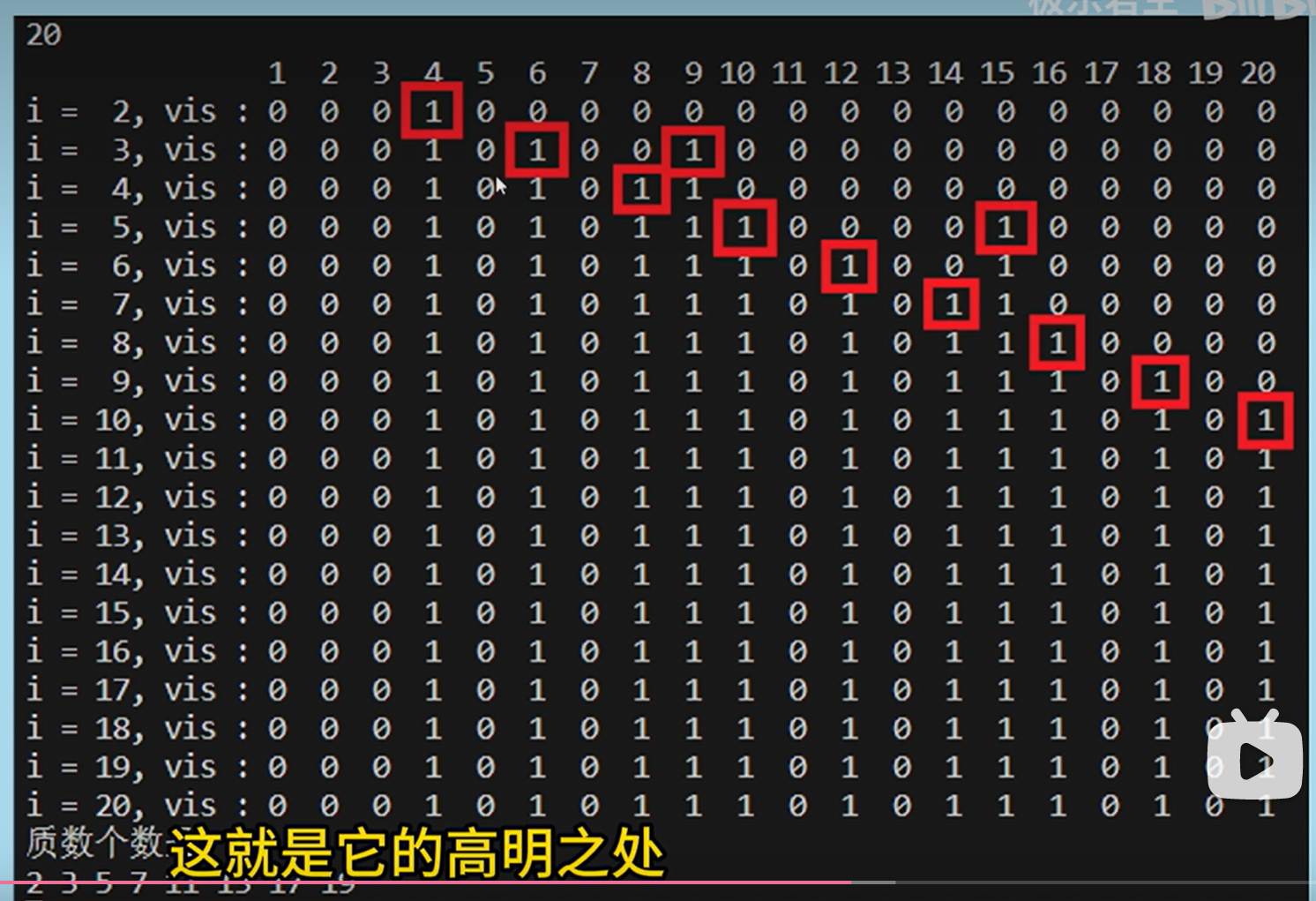
显然如果 x xx 是合数,那么 x xx 的倍数也一定是合数。利用这个结论,我们可以避免很多次不必要的检测。
我们可以从小到大枚举分析每一个数,然后同时把当前这个数的所有(比自己大的)倍数记为合数,那么运行结束的时候没有被标记的数就是素数了。
1 2 3 4 5 6 7 8 9 10 int v[N];void primes (int n{ memset (v, 0 , sizeof v); for (int i = 2 ;i <= n; ++ i){ if (v[i])continue ; cout << i << endl ; for (int j = i;j <= n / i; ++ j) v[i * j] = 1 ; } }
埃氏筛的时间复杂度为O ( n log log n ) ≈ O ( n ) O(n\log\log n)≈O(n) O ( n log log n ) ≈ O ( n ) O ( n ) O ( n ) O ( n ) ,随着 i 的增加, , 随着 i 的增加, , 随 着 i 的 增 加 , f ( n ) = 1 + 1 2 + 1 3 + 1 4 + 1 5 … + 1 n ≈ l o g l o g n f(n) = 1+\frac{1}{2}+\frac{1}{3}+\frac{1}{4}+\frac{1}{5}…+\frac{1}{n}≈loglogn f ( n ) = 1 + 2 1 + 3 1 + 4 1 + 5 1 … + n 1 ≈ l o g l o g n O ( n log log n ) O(n\log \log n) O ( n log log n )
线性筛法(欧拉筛法)
在欧拉筛我们可以保证每个数一定只会被它的最小质因子筛掉一次。由于 primes 数组中的质数是递增的。我们从小到大枚举 primes 数组,当第一次枚举到一个质数 primes [ j ] 满足primes [ j ] ∣ i \text{primes}[ j ] \mid i primes [ j ] ∣ i primes[ j ] 一定是 i 的最小质因子,primes[j] 也一定是 i × primes [ j ] i\times\text{primes}[j] i × primes [ j ] 而接下来 i × primes [ j + 1 ] i\times \text{primes}[j+1] i × primes [ j + 1 ] primes [ j ] 而不是` primes [ j + 1 ] ,故此时直接 break 即可。(这解释的太好了吧)
那么对于任意一个合数 x ,假设 x 的最小质因子为 y ,那么当枚举到$\frac{x}{y}<x $ 的时候一定会把 x 筛掉,即在枚举到 x 之前一定能把合数 x 筛掉,所以一定能把所有的合数都筛掉。
由于 保证每个合数只都被自己的最小质因子筛掉一遍 ,所以时间复杂度是 O ( n ) 的。(注意到筛法求素数的同时也得到了每个数的最小质因子,这是后面筛法求欧拉函数的关键)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vector <int > prime; void get_prime (int n) { vector <bool > mark (n+5 ) ; mark[1 ] = 1 ; for (int i = 2 ; i <= n; i++) { if (mark[i] == 0 ) prime.push_back(i); for (auto j : prime) { if (j * i > n) break ; mark[i * j] = 1 ; if (i % j == 0 ) break ; } } return ; }
“最小质因数 j× 最大因数(非自己):i = 这个合数:i*j”
我们必须保证在内层循环中枚举的每一个prime是合数i*j的最小质因子才行。
那就要保证i质因数分解之后不能有比j小的数字。
我们假设一下如果我们运行到某一个i%j==0的情况不实行break;(比如i=4,j=2)
那么继续运行把i=4,j=3 ,即43的最小质因数必不是3,因为我总能找到2,使得2<3为最小质因数 prime[i j]=12也给标记了,但事实上,12 的最小质因子不是3
而是2,那么到i=6,j=2的时候就会又标记一次,造成浪费
真不行就看链接内容吧:线性筛质数(欧拉筛)
例题:线性筛 复合 埃氏筛:黄题
给定区间 [ L , R ] [L,R] [ L , R ] 1 ≤ L ≤ R < 2 31 1\leq L\leq R < 2^{31} 1 ≤ L ≤ R < 2 3 1 R − L ≤ 1 0 6 R-L\leq 10^6 R − L ≤ 1 0 6
第一行,两个正整数 L L L R R R
一行,一个整数,表示区间中素数的个数。
纯纯线性筛会空间溢出:(错误代码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <vector> #include <algorithm> #define int long long using namespace std;vector<int > prime; signed main () int L,R;int minn=0 ,maxn; scanf ("%d %d" ,&L,&R); vector<bool > is_prime (R + 1 ) ; is_prime[1 ]=1 ; for (int i=2 ;i<=R;i++) { if (is_prime[i]==0 )prime.emplace_back (i); for (auto num:prime) { if (num*i>R)break ; is_prime[i*num]=1 ; if (i%num==0 )break ; } if (i==L-1 )minn=prime.size (); } maxn=prime.size (); printf ("%d" ,maxn-minn); return 0 ; }
于是我们经过思考看题解 发现:判定L~R区间的是否为质数,只需要线性筛到n \sqrt{n} n
即可在通过埃氏筛法确定L~R的所有素数,于是我们边欧筛边埃筛;
所以筛法的时候我们只要筛[2,R]就行了R \sqrt{R} R
时间复杂度:O(反正极限数据只要0.2s不到)R \sqrt{R} R
这里转换了算法,本来是用prime数组大小相减得到答案,现在改为用is_prime数组来求:
突破口就在于我们的l和r区间很小,我们就能够最后用循环遍历is_prime数组,以求出总素数数量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> #include <vector> #include <algorithm> #include <cmath> #define int long long using namespace std;vector<int > prime; signed main () int L,R; scanf ("%d %d" ,&L,&R); if (L==1 )L=2 ; vector<bool > is_prime_of_ltor (R-L+5 ) ; vector<bool > is_prime (sqrt(R) + 1 ) ; is_prime[1 ]=1 ; for (int i=2 ;i<=sqrt (R);i++) { if (is_prime[i]==0 )prime.emplace_back (i); for (auto num:prime) { if (num*i>sqrt (R))break ; is_prime[i*num]=1 ; if (i%num==0 )break ; } if (is_prime[i]==0 ) { int j; if (L%i==0 )j=L/i; else j=L/i+1 ; for (;j*i<=R;j++) { if (j*i!=i) is_prime_of_ltor[j*i-L]=1 ; } } } int ans=0 ; for (int i=0 ;i<=R-L;i++)ans+=(1 -is_prime_of_ltor[i]); printf ("%d" ,ans); return 0 ; }
0x12 $ Z^ $与 ( Z p ∗ , . ) (Z^*_p,^.) ( Z p ∗ , . ) Z ∗ Z^* Z ∗
( Z p ∗ , . ) (Z^*_p,^.) ( Z p ∗ , . ) Z p Z_p Z p ( 1 , 2 , … , p − 1 ) (1,2, \dots,p-1) ( 1 , 2 , … , p − 1 ) U ( Z p ) U(Z_p) U ( Z p )
0x12.1 唯一分解定理(算数基本定理) 任何一个大于 1的数都可以被分解成有限个质数乘积的形式
∏ i = 1 m p i C i = p 1 C 1 × p 2 C i × ⋯ × P n C n \prod_{i=1}^{m}p_i^{C^i}=p_1^{C_1}\times p_2^{C_i}\times \cdots \times P_n^{C_n}
i = 1 ∏ m p i C i = p 1 C 1 × p 2 C i × ⋯ × P n C n
其中 $p_1 < p_2 < ··· < p_m 为质数,
为质数, 为 质 数 , n \sqrt n n O ( n ) O(\sqrt n) O ( n )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int c[N],p[N];void divide (int n) { cnt = 0 ; for (int i = 2 ; i * i <= n; ++ i) { if (n % i == 0 ) { p[ ++ cnt] = i,c[cnt] = 0 ; while (n % i == 0 ) n /= i,c[cnt] ++ ; } } if (n > 1 ) p[ ++ cnt] = n,c[cnt] = 1 ; for (int i = 1 ;i <= cnt; ++ i) cout << p[i] << "^" << c[i] << endl ; }
对于数据较大的情况,如 n ≥ 1 0 18 n ≥ 10^{18} n ≥ 1 0 1 8 P o l l a r d R h o \tt Pollard\ Rho P o l l a r d R h o
Pollard-rho 算法是一个大数分解的随机算法,能够在 O ( n 1 4 ) O(n ^\frac{1}{4}) O ( n 4 1 )
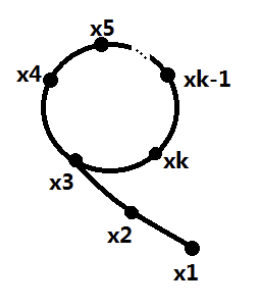
Pollard-rho 的策略为:从 [ 2 , n ) [2, n) [ 2 , n ) x 1 、 x 2 、 x 3 、 . . . 、 x k x_1、x_2、x_3、...、x_k x 1 、 x 2 、 x 3 、 . . . 、 x k x i 、 x j x_i、x_j x i 、 x j d = gcd ( x i − x j , n ) d = \gcd(x_i - x_j, n) d = g cd( x i − x j , n )
然后来看如何选取这 k个数,我们采用生成函数法,令 x 1 = r a n d ( ) % ( n − 1 ) + 1 x_1= rand()\%(n-1) + 1 x 1 = r a n d ( ) % ( n − 1 ) + 1
我们需要做的就是在它进入循环的时候及时跳出循环,因为x 1 x_1 x 1 x 1 x_1 x 1
为了判断环的存在,可以用一个简单的Floyd判圈算法,也就是"龟兔赛跑". 假设乌龟为t,兔子为r r r t = r = 1 t=r=1 t = r = 1 , t = i , r = 2 i ,t=i,r=2i , t = i , r = 2 i x t = x i , x r = x 2 i x_t=x_i,x_r=x_{2i} x t = x i , x r = x 2 i : x i = x i + c :x_i=x_i+c : x i = x i + c x r = x t x_r=x_t x r = x t x i = x 2 i = x i + k c x_i=x_2i=x_{i+kc} x i = x 2 i = x i + k c
这样以来,我们得到了一套基于Floyd判圈算法的Pollard Rho 算法.
Miller Rabin 算法是一种高效的质数判断方法。虽然是一种不确定的质数判断法,但是在选择多种底数的情况下,正确率是可以接受的。
Pollard rho 是一个非常玄学的方式,用于在 O ( n 1 / 4 ) O(n^{1/4}) O ( n 1 / 4 ) n n n O ( p ) O(\sqrt p) O ( p ) p p p n n n p p p n / p n/p n / p
这里我们要写一个程序,对于每个数字检验是否是质数,是质数就输出 Prime;如果不是质数,输出它最大的质因子是哪个。
第一行,T T T 350 350 3 5 0
以下 T T T n n n 2 ≤ n ≤ 10 18 2 \le n \le {10}^{18} 2 ≤ n ≤ 1 0 1 8
输出 T T T
对于每组测试数据输出结果。
1 2 3 4 5 6 7 6 2 13 134 8897 1234567654321 1000000000000
1 2 3 4 5 6 Prime Prime 67 41 4649 5
2018.8.14 新加数据两组,时限加大到 2s,感谢 @whzzt
2022.12.22 加入新的数据,感谢 @ftt2333 和 Library Checker
by @will7101
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 #include <iostream> #include <vector> #include <algorithm> #include <cmath> #include <ctime> #define int long long using namespace std ; int ans,T;int qmul (int a,int b ,int mod) { a%=mod; b%=mod; int c=(long double )a*b/mod; int ans=a*b-c*mod; return (ans%mod+mod)%mod; } int qpow (int flor,int m,int n) { int ret=1 ; while (m) { if (m%2 ==1 )ret=qmul(ret,flor,n); flor=qmul(flor,flor,n); m/=2 ; } return (ret+n)%n; } bool miller_rabbin_one (int n) { if (n==2 )return true ; if (n<2 || n%2 ==0 )return false ; int m=n-1 ; int k=0 ; while (m%2 ==0 ) { m/=2 ;k++;} int recordk=k; vector <int > primes = {2 , 3 , 5 , 7 , 11 , 13 , 17 , 19 , 23 ,29 ,31 ,37 }; for (int inode : primes) { if (n==inode)return true ; int pre=qpow(inode,m,n),next=pre; if (pre==1 ) continue ; k=recordk; while (k--) { next=qmul(pre,pre,n); if (next==1 && pre!=1 && pre!=n-1 )return false ; pre=next; } if (pre!=1 )return false ; } return true ; } int f (int x, int c, int n) { return (qmul(x , x ,n)+ c) % n; } int gcd (int x, int y) { if (!x) return y; if (!y) return x; int t = __builtin_ctzll(x | y); x >>= __builtin_ctzll(x); do { y >>= __builtin_ctzll(y); if (x > y) swap(x, y); y -= x; } while (y); return x << t; } int pollard_rho (int N) { if (N %2 ==0 ) return 2 ; if (miller_rabbin_one(N) == true ) return N; int t=rand()%(N+1 ); int c = rand() % (N + 1 ) ; int tur=t;int rab=t; while (true ) { tur = f(tur, c, N); rab = f(f(rab, c, N), c, N); int d = gcd(abs (tur - rab), N); if (d > 1 && d<N) return d; if (tur==rab)return pollard_rho(N); } } void find_max_primeofn (int N) { if (N<=1 )return ; if (miller_rabbin_one(N)) { ans=max(ans,N); return ; } int u=pollard_rho(N); find_max_primeofn(u); find_max_primeofn(N/u); } signed main () { srand(time(NULL )); scanf ("%lld" ,&T); while (T--) { int N; scanf ("%lld" ,&N); if (miller_rabbin_one(N) == true ) printf ("Prime\n" ); else { ans=0 ;find_max_primeofn(N); printf ("%lld\n" ,ans); } } return 0 ; }
0x12.2 Z ∗ Z^*Z
若
n = p 1 α 1 × p 2 α 2 × p 3 α 3 × ⋯ × p k α k m = p 1 β 1 × p 2 β 2 × p 3 β 3 × ⋯ × p k β k n=p_1^{α_1}\times p_2^{α_2}\times p_3^{α_3}\times \cdots\times p_k^{α_k}
\\m=p_1^{β_1}\times p_2^{β_2}\times p_3^{β_3}\times \cdots\times p_k^{β_k}
n = p 1 α 1 × p 2 α 2 × p 3 α 3 × ⋯ × p k α k m = p 1 β 1 × p 2 β 2 × p 3 β 3 × ⋯ × p k β k
则
n × m = p 1 α 1 + β 1 × p 2 α 2 + β 2 × p 3 α 3 + β 3 × ⋯ × p k α k + β k gcd ( n , m ) = p 1 min { α 1 , β 1 } × p 2 min { α 1 , β 1 } × ⋯ × p k min { α k , β k } lcm ( n , m ) = p 1 max { α 1 , β 1 } × p 2 max { α 1 , β 1 } × ⋯ × p k max { α k , β k } \begin{array}{l}
n\times m=p_1^{α_1+β_1}\times p_2^{α_2+β_2}\times p_3^{α_3+β_3}\times \cdots\times p_k^{α_k+β_k}
\\\gcd(n,m)=p_1^{\min\{α_1,β_1\}}\times p_2^{\min\{α_1,β_1\}}\times \cdots\times p_k^{\min\{α_k,β_k\}}
\\\text{lcm}(n,m)=p_1^{\max\{α_1,β_1\}}\times p_2^{\max\{α_1,β_1\}}\times \cdots\times p_k^{\max\{α_k,β_k\}}
\end{array}
n × m = p 1 α 1 + β 1 × p 2 α 2 + β 2 × p 3 α 3 + β 3 × ⋯ × p k α k + β k g cd( n , m ) = p 1 m i n { α 1 , β 1 } × p 2 m i n { α 1 , β 1 } × ⋯ × p k m i n { α k , β k } lcm ( n , m ) = p 1 m a x { α 1 , β 1 } × p 2 m a x { α 1 , β 1 } × ⋯ × p k m a x { α k , β k }
定理12.2.2::$ (p-1)!+1 \equiv0\ (\mod p)$
定理12.2.3: ( ( n + 1 ) ( n + 2 ) . . . ( n + k ) ) % k ≠ 0 ((n+1)(n+2)...(n+k))\%k≠0 ( ( n + 1 ) ( n + 2 ) . . . ( n + k ) ) % k = 0
0x12.3( Z p ∗ , . ) (Z^*_p,^.) ( Z p ∗ , . ) ( Z p ∗ , . ) (Z^*_p,^.) ( Z p ∗ , . ) a ∈ Z p ∗ a\in Z^*_p a ∈ Z p ∗ Z p ∗ = { a n ∣ n = 1 , 2 , ⋯ , p − 1 } Z^*_p=\{ a^n|n=1,2,\cdots,p-1\} Z p ∗ = { a n ∣ n = 1 , 2 , ⋯ , p − 1 }
这样的 a称为 p 的原根。
素数一定有原根,原根不唯一,部分合数也有原根
1000000007 的原根为5
998244353 的原根为 3
原根详见0x60原根