[JLOI2009] 二叉树问题
题目描述
如下图所示的一棵二叉树的深度、宽度及结点间距离分别为:
- 深度:
- 宽度:
- 结点 8 和 6 之间的距离:
- 结点 7 和 6 之间的距离:
其中宽度表示二叉树上同一层最多的结点个数,节点 之间的距离表示从 到 的最短有向路径上向根节点的边数的两倍加上向叶节点的边数。
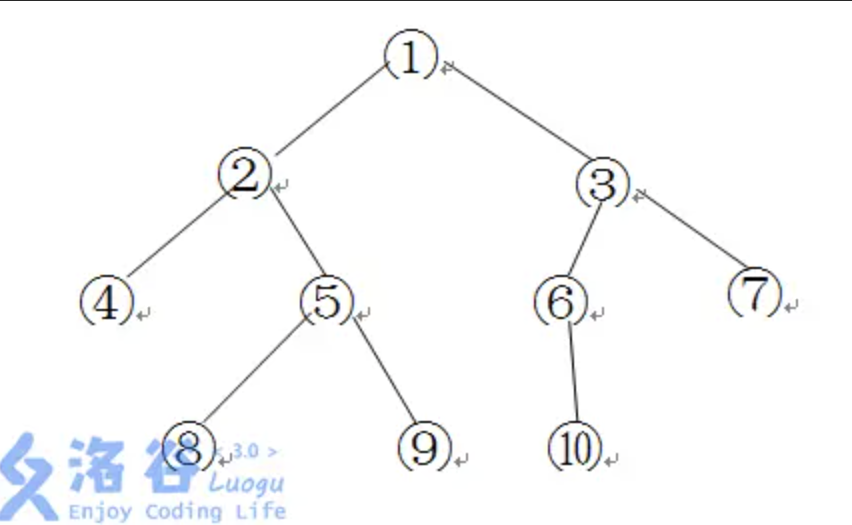
给定一颗以 1 号结点为根的二叉树,请求出其深度、宽度和两个指定节点 之间的距离。
输入格式
第一行是一个整数,表示树的结点个数 。
接下来 行,每行两个整数 ,表示树上存在一条连接 的边。
最后一行有两个整数 ,表示求 之间的距离。
输出格式
输出三行,每行一个整数,依次表示二叉树的深度、宽度和 之间的距离。
样例 #1
样例输入 #1
1 | 10 |
样例输出 #1
1 | 4 |
提示
对于全部的测试点,保证 ,且给出的是一棵树。
相当于分解成三个问题是吧。
1.求最大深度(深度优先搜索算法解决)
MY思路
1 | void depth(int p) |
dalao思路
1 | struct node{ |
直接在结构体里面定义了一个深度属性
1 | a[y].deep=a[x].deep+1;//遍历树,后一项深度等于前一项加一 |
2.最大宽度
my思路(迭代版本 广度优先搜索)
1 | void breath() |
dalao思路
直接利用第一题的deep,deep相同的在一个桶数组中加在一起
1 | for(int i=1;i<=n;i++) //把每一个深度有多少个节点记录 |
3.路径长度
my思路(深度优先搜索)
1 | void search(int node,int come)//come表示这个节点是怎么被寻找到的(方便回溯) 1:父节点找左子树,2:父节点找右子树3:左子树找父节点4:右子树找父节点 |
dalao思路(lca算法)
普及一下
最近公共祖先
简单引入
对于有根树T的两个结点u、v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u、v的祖先且x的深度尽可能大。
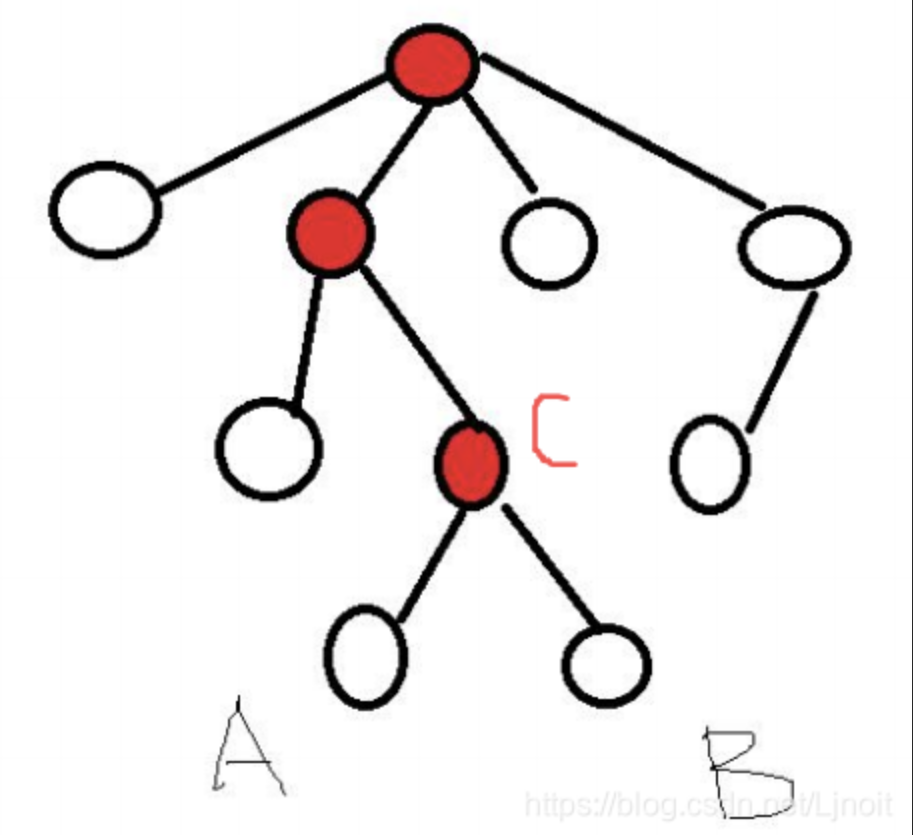
红色的都是是A和B的公共祖先,但只有最近的C才是最近公共祖先。
LCA问题是树上的一个经典问题,在很多方面有着广泛的应用,比如求LCP(最长公共前缀),接下来我们就来介绍他的几种算法。
LCA的算法
暴力枚举法
如果我们要求a和b的最近公共祖先,就沿着父亲的方向把a的所有祖先都标记一下(类似并查集找父亲,但是没有路径压缩),然后在从b开始往上找祖先,碰到第一个被标记的点,就是a和b的最近公共祖先。
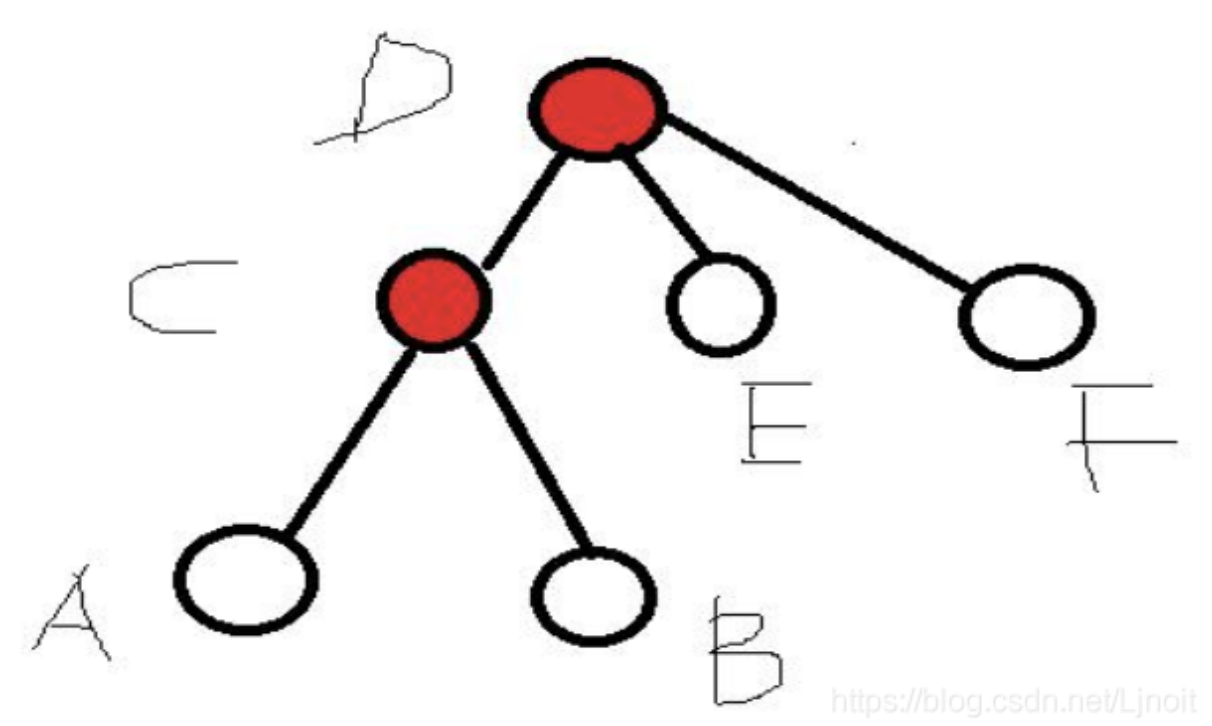
C是最近公共祖先。
求一个对点的LCA时间复杂度高达O(N)。
求m个点对的LCA时间复杂度高达O(mN)。
当m和n都高达10万的时候,超时了!!!
宝宝难以承受!!!!!
求m个点对的最近公共祖先是可以优化的,一般有两种:
1、离线算法(Tarjan离线算法):所谓的离线算法指的是把所有问题收集起来以后一起去算,最后一起回答。
2、在线算法(倍增算法):所谓的在线算法就是来一个点对,处理一个点对。
Tarjan离线算法
Robert Tarjan设计了求解的应用领域的许多问题的广泛有效的算法和数据结构。 他已发表了超过228篇理论文章(包括杂志,一些书中的一些章节文章等)。Robert Tarjan以在数据结构和图论上的开创性工作而闻名。 他的一些著名的算法包括 Tarjan最近共同祖先离线算法 ,Tarjan的强连通分量算法等。其中Hopcroft-Tarjan平面嵌入算法是第一个线性时间平面算法。Tarjan也开创了重要的数据结构如:斐波纳契堆和splay树(splay发明者还有Daniel Sleator)。另一项重大贡献是分析了并查集。他是第一个证明了计算反阿克曼函数的乐观时间复杂度的科学家。(此段来自百度百科,有删改)
简单的介绍一下tarjan算法:
tarjan算法是离线算法,它必须先将所有的要查询的点对存起来,然后在搜的时候输出结果。
tarjan算法很经典,因为算法的思想很巧妙,利用了并查集思想,在dfs下,将查询一步一步的搜出来。
基本思路:
下面给出真代码:
1 | int f[N],n,m,ans[N],check[N]; |
我们在深度优先遍历的时候,先遍历x节点的左子树,当遍历到u的时候,发现v没有被遍历过,那么就不去管lca(u,v)这个问题,然后我们把已经遍历的x子树的所有节点都合并到他的父亲(即father指向父亲),然后当我们遍历到v的时候,发现u已经遍历过了,那么此时u在并查集里的father就是u和v的最近公共祖先.
时间复杂度:由于每个点只遍历一次,每个问题只枚举2次,所以时间复杂度是O(N+2Mα(N))。α(N)为并查集查询一次根所需要的时间。
倍增算法
首先一个小问题,给你两个点a和b,你如何快速的回答这两个点在树里面是否具有祖先和后代的关系。
暴力算法又是o(N),明显太浪费时间!
引入时间戳的概念:所谓的时间戳就是在给一棵树进行深度优先遍历的同时,记录下计入每个点的时候和离开每个点的时间。
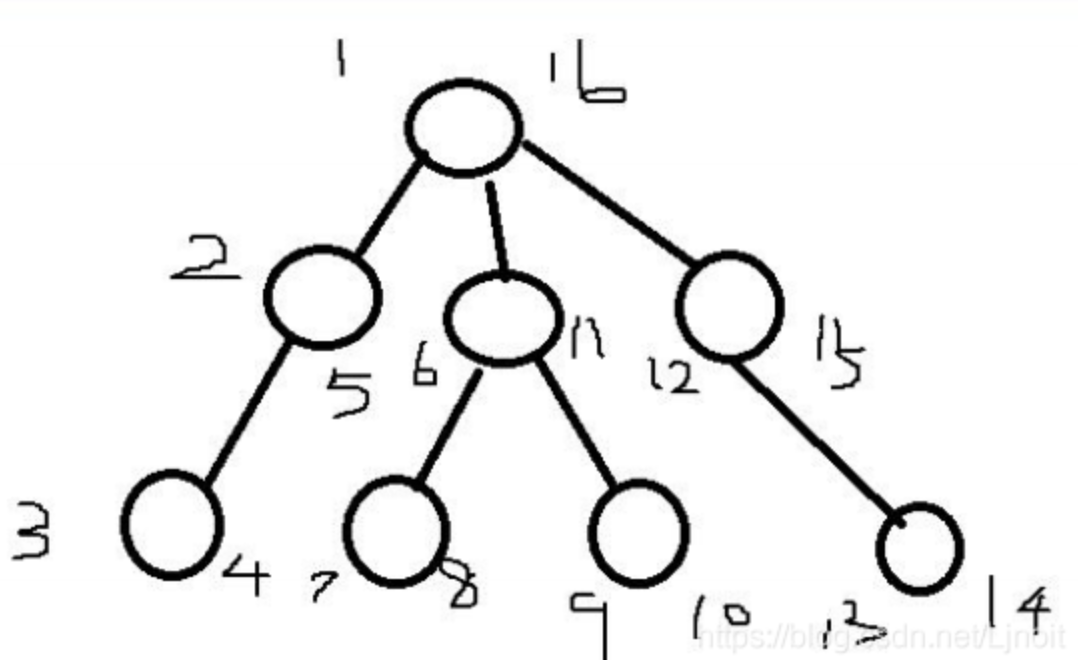
如图所示,每个节点的左边是进入的时间,右边是离开的时间。
如果a是b的祖先,只要满足 (in[a]<=in[b]) and (out[b]<=out[a])
也就是我们只需要一次深搜,接下来对于任何询问a和b是否有祖先关系的时候,我们只要O(1)的时间就能回答这个问题。
建立倍增数组:
定义f[i][j]为与节点i距离为2^j的祖先的编号。
明显的f[i][0]就是每个点直接的父亲。
另有递推关系:f[i][j]=f[f[i][j-1],j-1]。
于是我们只需要在nlogn的时间内就可以求出f数组的值。
如果f[i][j]不存在,我们就令f[i][j]=根,方便我们计算
接下来如何求a和b的最近公共祖先呢?
1、如果a是b的祖先,那么输出a
2、如果b是a的祖先,那么输出b
3、for i:=20 downto 0 do
if f[a][i]不是b的祖先,那么令 a=f[a][i];
循环结束的时候,f[a][0]就是最近公共祖先。
1 | int lca(int x,int y) { |
1 | int lca(int x,int y){ //最最重要!!!求最近公共祖先 |
上面最后一个代码是实现本题目的代码哦
完结!

