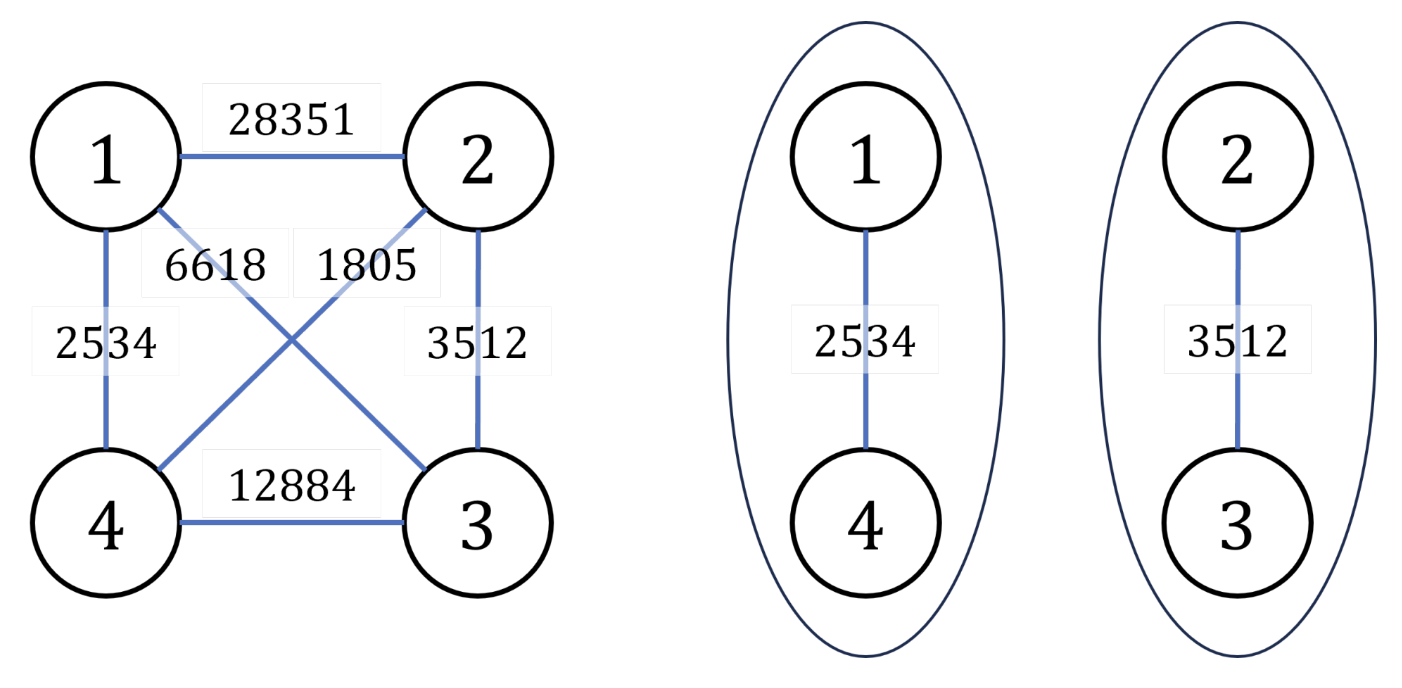
S 城现有两座监狱,一共关押着 N 名罪犯,编号分别为 1∼N。他们之间的关系自然也极不和谐。很多罪犯之间甚至积怨已久,如果客观条件具备则随时可能爆发冲突。我们用“怨气值”(一个正整数值)来表示某两名罪犯之间的仇恨程度,怨气值越大,则这两名罪犯之间的积怨越多。如果两名怨气值为 c 的罪犯被关押在同一监狱,他们俩之间会发生摩擦,并造成影响力为 c 的冲突事件。
每年年末,警察局会将本年内监狱中的所有冲突事件按影响力从大到小排成一个列表,然后上报到 S 城 Z 市长那里。公务繁忙的 Z 市长只会去看列表中的第一个事件的影响力,如果影响很坏,他就会考虑撤换警察局长。
在详细考察了 N 名罪犯间的矛盾关系后,警察局长觉得压力巨大。他准备将罪犯们在两座监狱内重新分配,以求产生的冲突事件影响力都较小,从而保住自己的乌纱帽。假设只要处于同一监狱内的某两个罪犯间有仇恨,那么他们一定会在每年的某个时候发生摩擦。
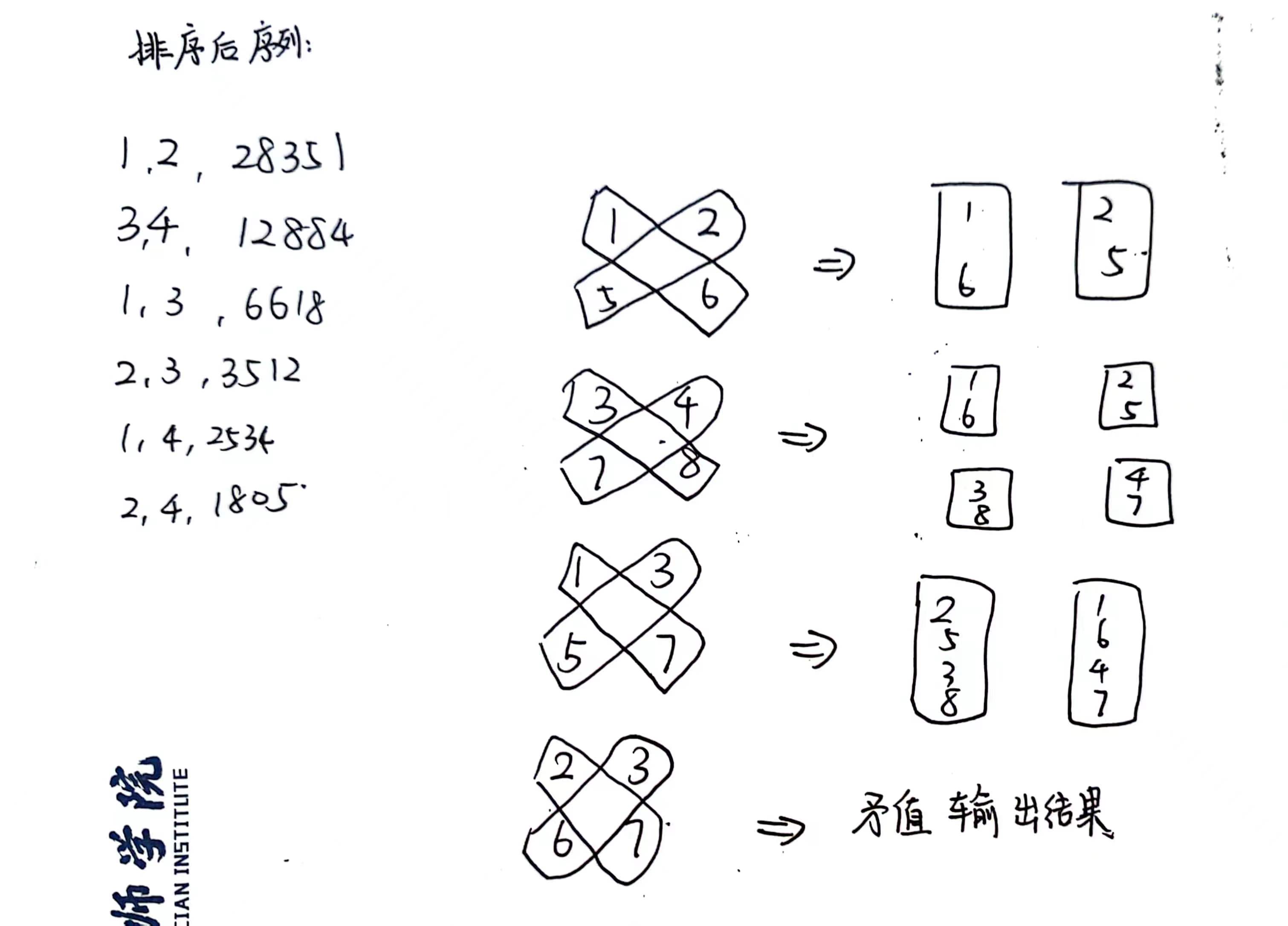
#include<cstdio> #include<cctype> #include<algorithm> intread()//快速读入,可忽略 { int ans = 0; char c = getchar(); while (!isdigit(c)) c = getchar(); while (isdigit(c)) { ans = (ans << 3) + (ans << 1) + c - '0'; c = getchar(); } return ans; } structdata//以结构体方式保存便于排序 { int a, b, w; } C[100005]; intcmp(data &a, data &b) { return a.w > b.w; } int fa[40005], rank[40005]; //以下为并查集 intfind(int a) { return (fa[a] == a) ? a : (fa[a] = find(fa[a])); } intquery(int a, int b) { returnfind(a) == find(b); } voidmerge(int a, int b) { int x = find(a), y = find(b); if (rank[x] >= rank[y]) fa[y] = x; else fa[x] = y; if (rank[x] == rank[y] && x != y) rank[x]++; } voidinit(int n) { for (int i = 1; i <= n; ++i) { rank[i] = 1; fa[i] = i; } } intmain() { int n = read(), m = read(); init(n * 2); //对于罪犯i,i+n为他的敌人 for (int i = 0; i < m; ++i) { C[i].a = read(); C[i].b = read(); C[i].w = read(); } std::sort(C, C + m, cmp); for (int i = 0; i < m; ++i) { if (query(C[i].a, C[i].b)) //试图把两个已经被标记为“朋友”的人标记为“敌人” { printf("%d\n", C[i].w); //此时的怒气值就是最大怒气值的最小值 break; } merge(C[i].a, C[i].b + n); merge(C[i].b, C[i].a + n); if (i == m - 1) //如果循环结束仍无冲突,输出0 puts("0"); } return0; }