并·查·集
需要解决的问题:
【模板】并查集
题目描述
如题,现在有一个并查集,你需要完成合并和查询操作。
输入格式
第一行包含两个整数 ,表示共有 个元素和 个操作。
接下来 行,每行包含三个整数 。
当 时,将 与 所在的集合合并。
当 时,输出 与 是否在同一集合内,是的输出
Y ;否则输出 N 。
输出格式
对于每一个 的操作,都有一行输出,每行包含一个大写字母,为 Y 或者 N 。
样例 #1
样例输入 #1
1 | 4 7 |
样例输出 #1
1 | N |
提示
对于 的数据,,。
对于 的数据,,。
对于 的数据,,,,。
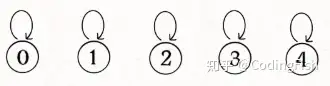
1.初始化
因为我们在初始化的时候,每个节点的根节点初始化为它自己,即我爸爸是我自己,这就是根节点和其他节点的不同之处,当 r==fa[r] 的时候,就说明 r 是根节点.
1 | void init() |
2.查(“查”的意思是查找一个结点的根节点.)
初始化一个fa数组,里面存放每个节点的的父节点( fa[i]=i 的父节点)
fa数组可以表示一颗树,其目的是为了查根节点,根据这个数组,我们就可以“顺藤摸瓜”,找到每个节点的根节点。
假如你在一个大家族里,大家族中的每个人都知道自己的父亲是谁,当有一天,你问你爸爸我的祖先是谁呀?你爸爸就会先问你爷爷,你爷爷就问你太爷爷,最后就能追溯到祖先 root.
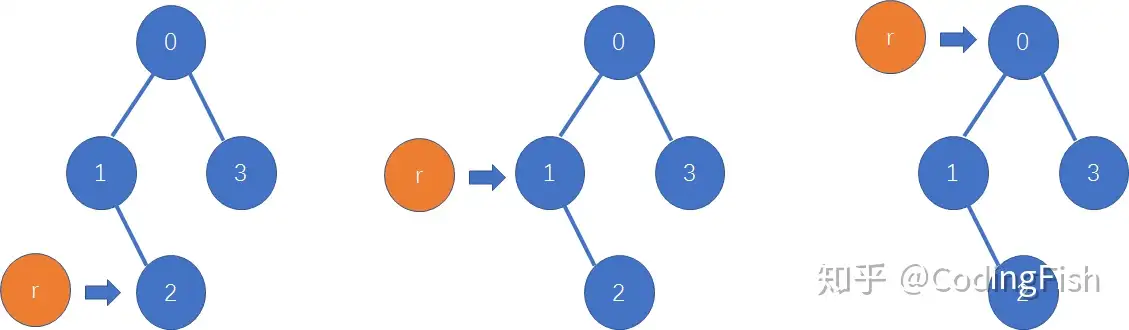
于是我们可以写出find函数(未经过路径压缩版本)
1 | int find(int x) |
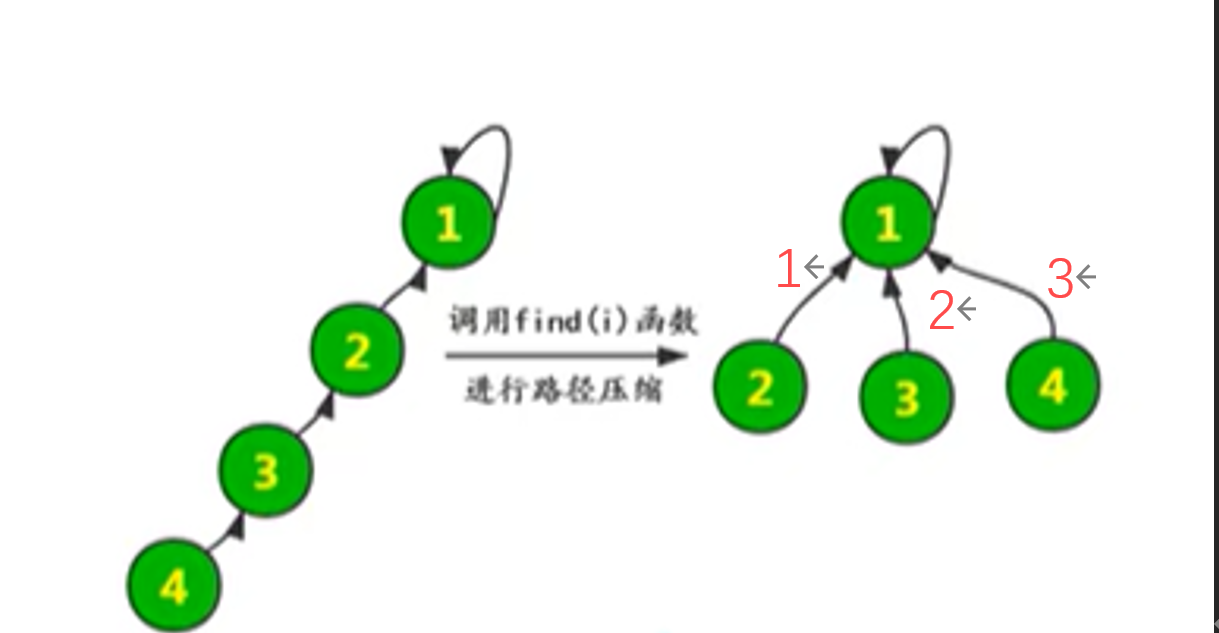
路径压缩
最简单的并查集效率是比较低的。例如,来看下面这个场景:
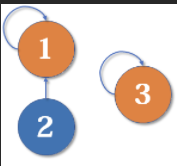
现在我们要merge(2,3),于是从2找到1,fa[1]=3,于是变成了这样:

然后我们又找来一个元素4,并需要执行merge(2,4):
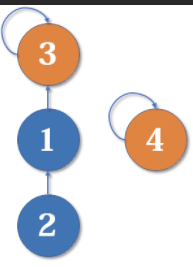
从2找到1,再找到3,然后fa[3]=4,于是变成了这样:

大家应该有感觉了,这样可能会形成一条长长的链,随着链越来越长,我们想要从底部找到根节点会变得越来越难。
怎么解决呢?我们可以使用路径压缩的方法。既然我们只关心一个元素对应的根节点,那我们希望每个元素到根节点的路径尽可能短,最好只需要一步,像这样:

其实这说来也很好实现。只要我们在查询的过程中,把沿途的每个节点的父节点都设为根节点即可。下一次再查询时,我们就可以省很多事。这用递归的写法很容易实现:
合并(路径压缩)
1 | int find(int x) |
以上代码常常简写为一行:
1 | int find(int x) |
注意赋值运算符=的优先级没有三元运算符?:高,这里要加括号。
路径压缩优化后,并查集的时间复杂度已经比较低了,绝大多数不相交集合的合并查询问题都能够解决。然而,对于某些时间卡得很紧的题目,我们还可以进一步优化。
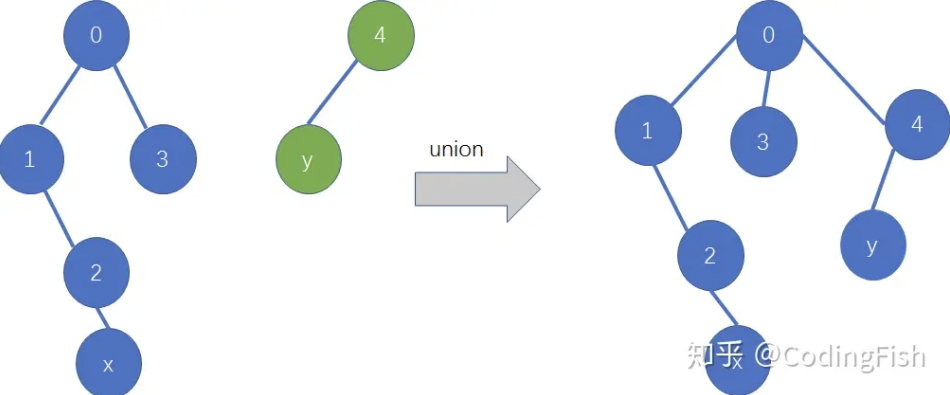
3.并(“并”指把两个在同一连通分量的结点合并)
比如有两个节点 x和y, 我们就查一下x的根节点和y的根节点(并的时候用到了查)是不是同一个节点(咱们的祖先是不是同一个人),如果是,那么x和y本来就是一家人,不用做任何操作。
如果发现x和y的祖先不同,必须有一个人要迁移户口,例如就让y的祖先做x祖先的儿子,这样x 和 y还是成为一家人了(实现了并操纵)。
代码如下:
1 | void merge(int x,int y) |
并查集的生动阐释:
以上题目的参考代码:
1 |
|
例题:需要记录压缩路径长度,和集合总长度的变式
[NOI2002] 银河英雄传说
题目背景
公元 年,地球居民迁至金牛座 第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年,并开始向银河系深处拓展。
宇宙历 年,银河系的两大军事集团在巴米利恩星域爆发战争。泰山压顶集团派宇宙舰队司令莱因哈特率领十万余艘战舰出征,气吞山河集团点名将杨威利组织麾下三万艘战舰迎敌。
题目描述
杨威利擅长排兵布阵,巧妙运用各种战术屡次以少胜多,难免恣生骄气。在这次决战中,他将巴米利恩星域战场划分成 列,每列依次编号为 。之后,他把自己的战舰也依次编号为 ,让第 号战舰处于第 列,形成“一字长蛇阵”,诱敌深入。这是初始阵形。当进犯之敌到达时,杨威利会多次发布合并指令,将大部分战舰集中在某几列上,实施密集攻击。合并指令为 M i j,含义为第 号战舰所在的整个战舰队列,作为一个整体(头在前尾在后)接至第 号战舰所在的战舰队列的尾部。显然战舰队列是由处于同一列的一个或多个战舰组成的。合并指令的执行结果会使队列增大。
然而,老谋深算的莱因哈特早已在战略上取得了主动。在交战中,他可以通过庞大的情报网络随时监听杨威利的舰队调动指令。
在杨威利发布指令调动舰队的同时,莱因哈特为了及时了解当前杨威利的战舰分布情况,也会发出一些询问指令:C i j。该指令意思是,询问电脑,杨威利的第 号战舰与第 号战舰当前是否在同一列中,如果在同一列中,那么它们之间布置有多少战舰。
作为一个资深的高级程序设计员,你被要求编写程序分析杨威利的指令,以及回答莱因哈特的询问。
输入格式
第一行有一个整数 (),表示总共有 条指令。
以下有 行,每行有一条指令。指令有两种格式:
-
M i j: 和 是两个整数(),表示指令涉及的战舰编号。该指令是莱因哈特窃听到的杨威利发布的舰队调动指令,并且保证第 号战舰与第 号战舰不在同一列。 -
C i j: 和 是两个整数(),表示指令涉及的战舰编号。该指令是莱因哈特发布的询问指令。
输出格式
依次对输入的每一条指令进行分析和处理:
- 如果是杨威利发布的舰队调动指令,则表示舰队排列发生了变化,你的程序要注意到这一点,但是不要输出任何信息。
- 如果是莱因哈特发布的询问指令,你的程序要输出一行,仅包含一个整数,表示在同一列上,第 号战舰与第 号战舰之间布置的战舰数目。如果第 号战舰与第 号战舰当前不在同一列上,则输出 。
样例 #1
样例输入 #1
1 | 4 |
样例输出 #1
1 | -1 |
提示
样例解释
战舰位置图:表格中阿拉伯数字表示战舰编号。
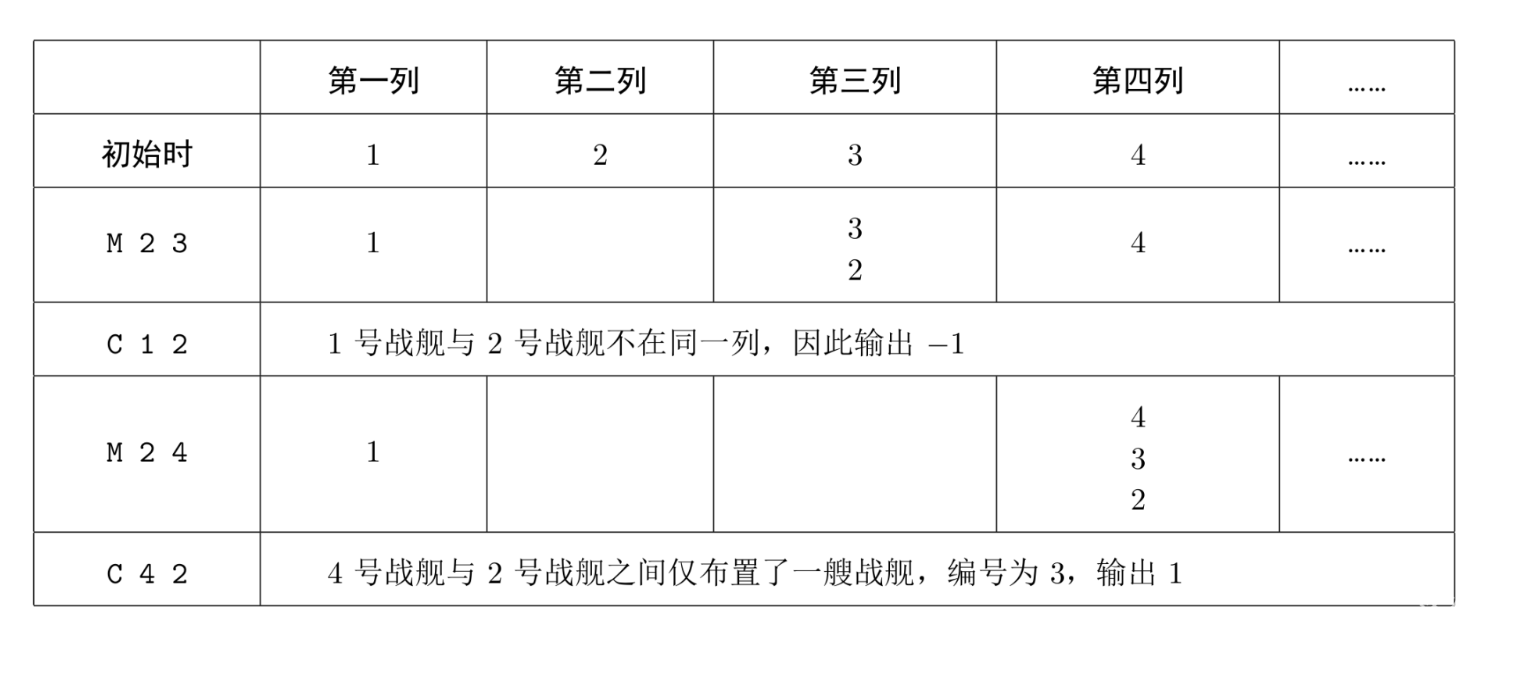
解析:
fa[]数组维护两个编号之间的连通性,dis[]维护编号为i的战舰到fa[i]之间的距离,num[]维护编号为i的战舰所在的那一列有多少战舰。
记录距离根节点的距离显得尤为重要,其中距离根节点的距离存储在dis数组内
1 | int find(int x) |
于是合并函数可以修改如下:
1 | void merge(int x,int y) |
每一次输出只用输出abs(dis[x]-dis[y])-1;即可
注意,这里是问中间有几个城市, 不算两边,所以要-1
完整代码如下:
1 |
按秩合并
有些人可能有一个误解,以为路径压缩优化后,并查集始终都是一个菊花图(只有两层的树的俗称)。但其实,由于路径压缩只在查询时进行,也只压缩一条路径,所以并查集最终的结构仍然可能是比较复杂的。例如,现在我们有一棵较复杂的树需要与一个单元素的集合合并:
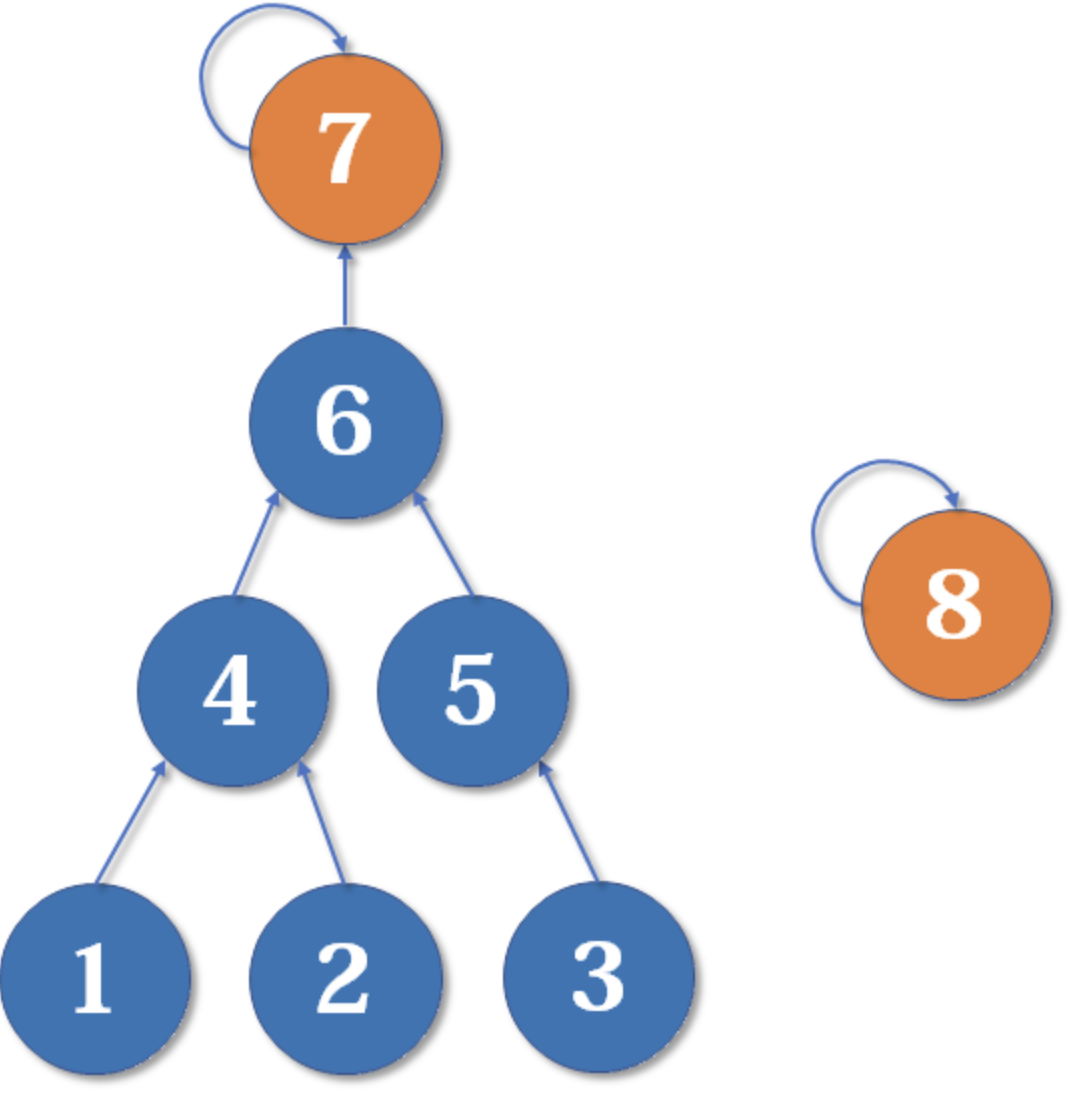
假如这时我们要merge(7,8),如果我们可以选择的话,是把7的父节点设为8好,还是把8的父节点设为7好呢?
当然是后者。因为如果把7的父节点设为8,会使树的深度(树中最长链的长度)加深,原来的树中每个元素到根节点的距离都变长了,之后我们寻找根节点的路径也就会相应变长。虽然我们有路径压缩,但路径压缩也是会消耗时间的。而把8的父节点设为7,则不会有这个问题,因为它没有影响到不相关的节点。
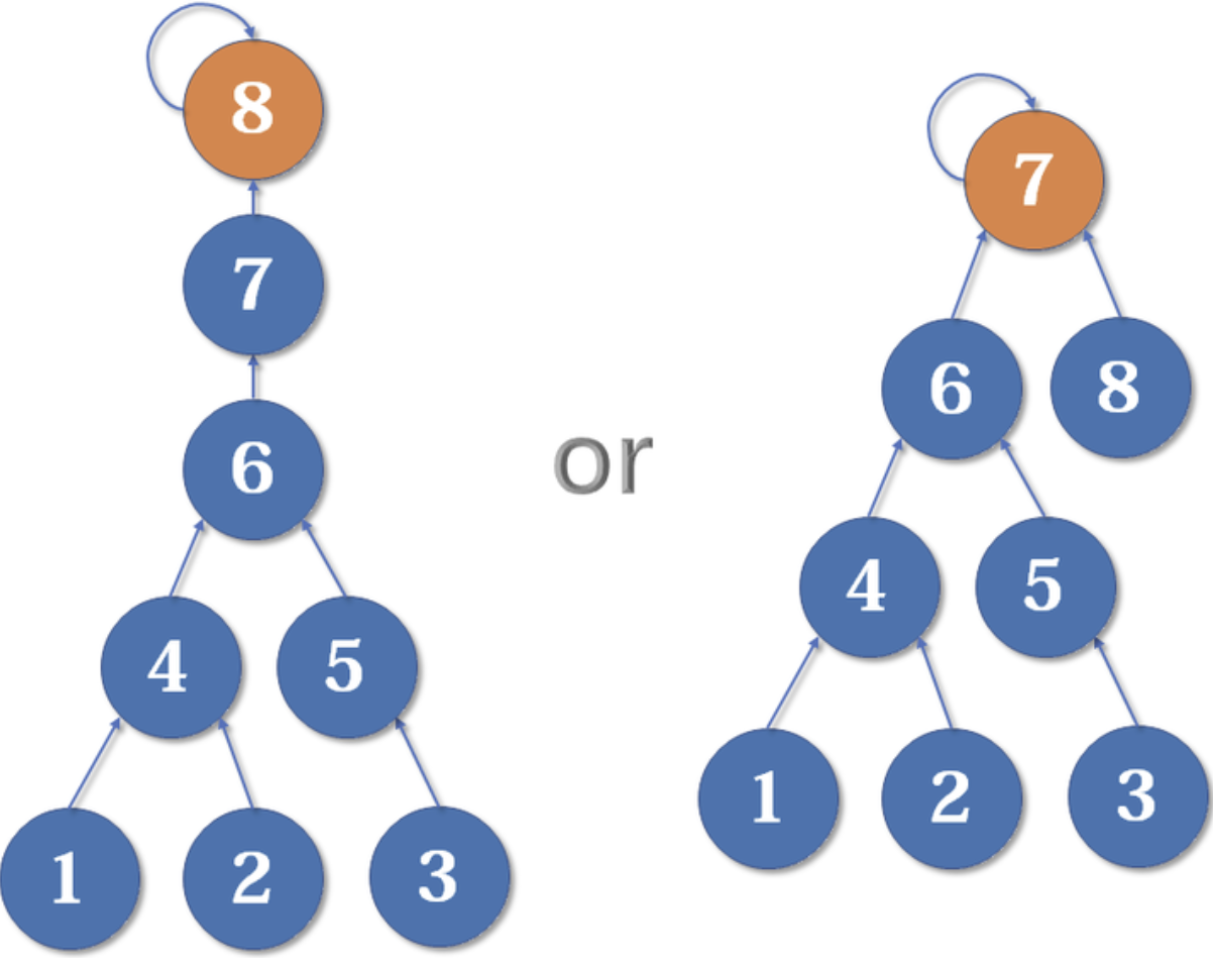
这启发我们:我们应该把简单的树往复杂的树上合并,而不是相反。因为这样合并后,到根节点距离变长的节点个数比较少。
我们用一个数组rank[]记录每个根节点对应的树的深度(如果不是根节点,其rank相当于以它作为根节点的子树的深度)。一开始,把所有元素的rank(秩)设为1。合并时比较两个根节点,把rank较小者往较大者上合并。
路径压缩和按秩合并如果一起使用,时间复杂度接近 ,但是很可能会破坏rank的准确性。
初始化(按秩合并)
1 | inline void init(int n) |
合并(按秩合并)
1 | inline void merge(int i, int j) |
为什么深度相同,新的根节点深度要+1?如下图,我们有两个深度均为2的树,现在要merge(2,5):
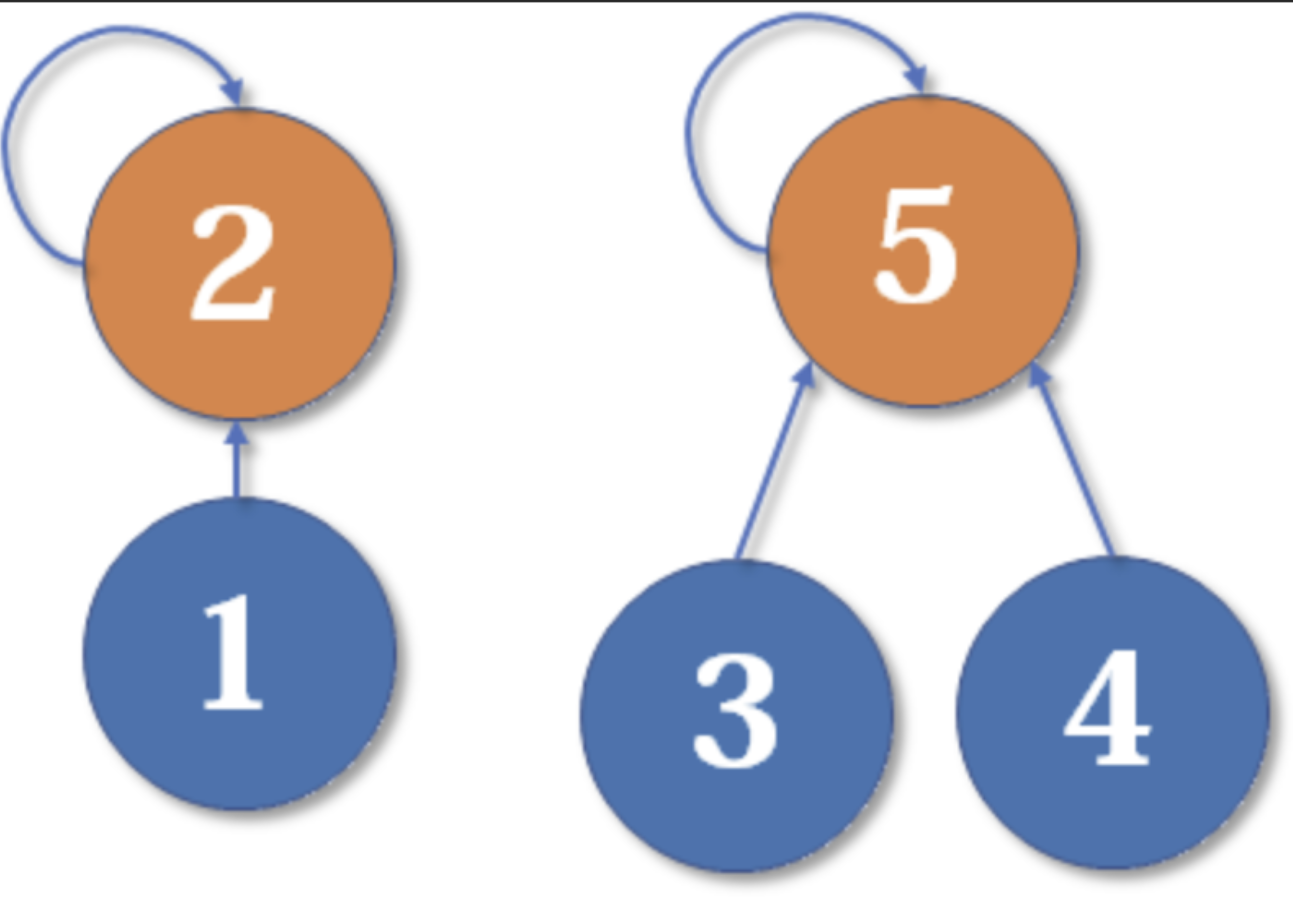
这里把2的父节点设为5,或者把5的父节点设为2,其实没有太大区别。我们选择前者,于是变成这样:
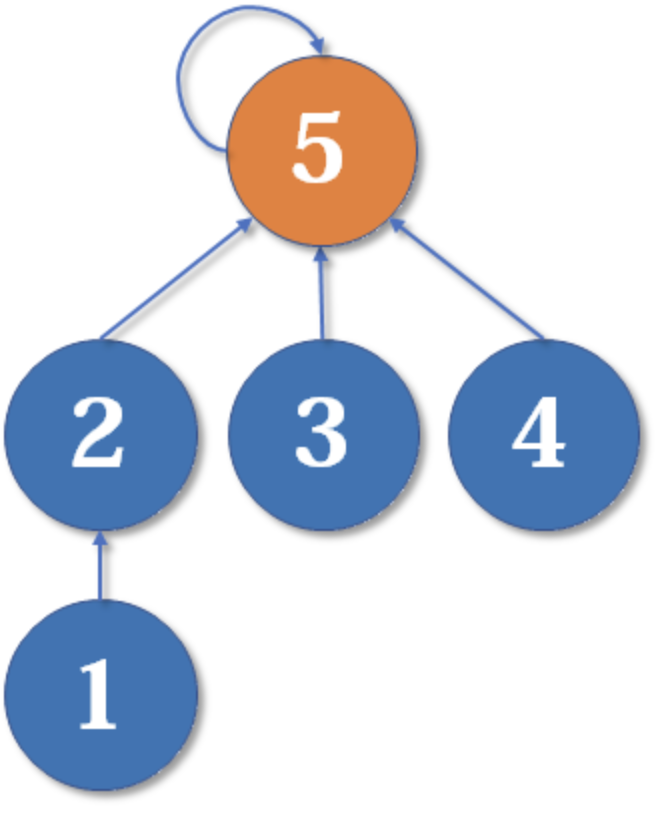
显然树的深度增加了1。另一种合并方式同样会让树的深度+1。

